We introduce the concept of synthetic artifact auditing. Given a target artifact, we aim to determine whether the synthetic data was involved in the developing process.
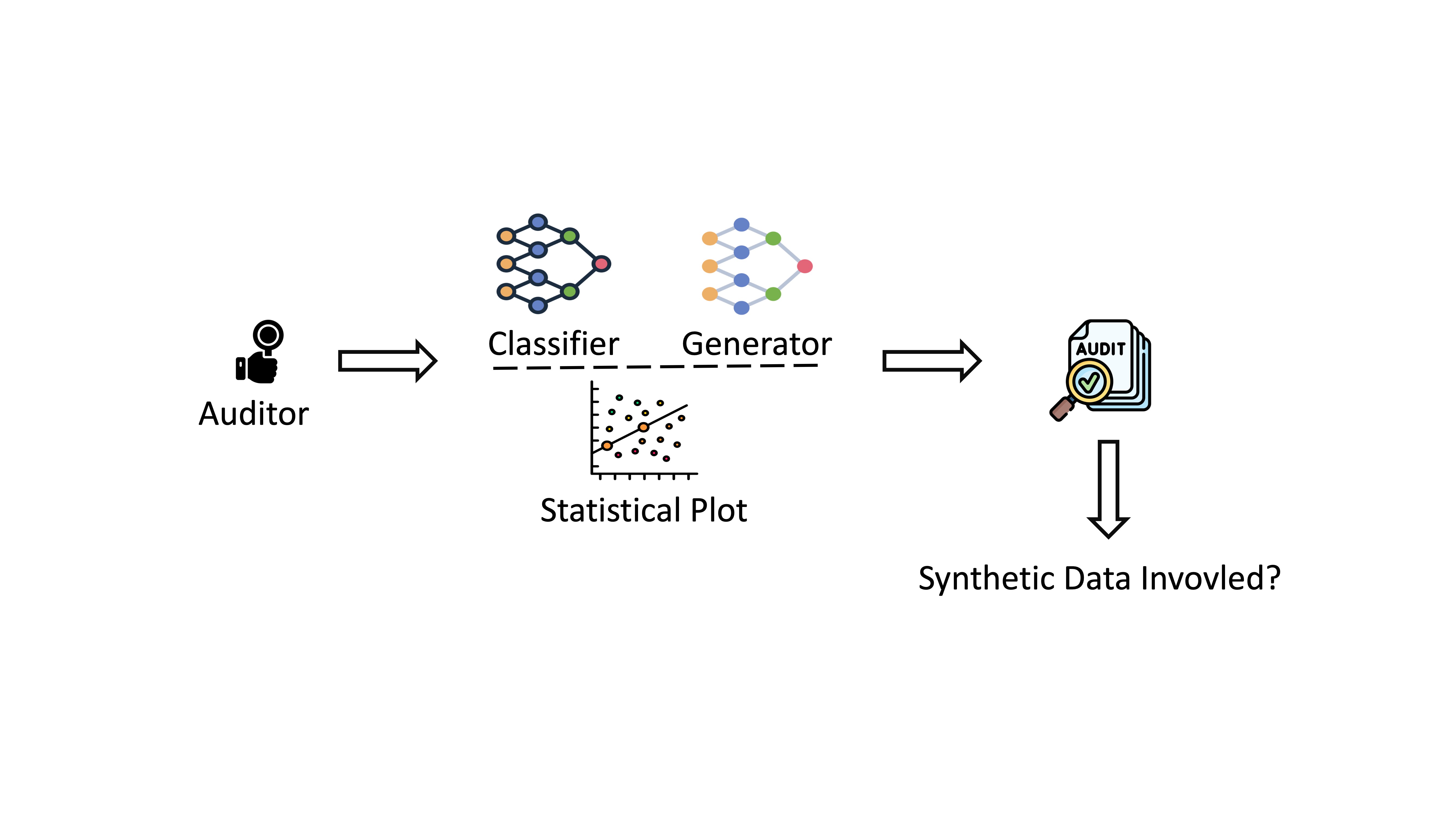
We introduce the concept of synthetic artifact auditing. Given a target artifact, we aim to determine whether the synthetic data was involved in the developing process.
Synthetic data have the potential to contain biases and hallucination. In downstream training and analysis process, the bias and inaccurate information could undermine the reliability of the decision-making process.
Thinking of a real life example of treating potential risks to the consumers with allergies, the allergen labeling is a practice to identifies and discloses the presence of potential allergens in food products to protect consumers with allergies.
In the same vein, to raise users’ awareness and thereby reduce unexpected consequences and risks in downstream applications, it is necessary to label those trained on or derived from synthetic data!
Furthermore, many AI companies have usage terms that prohibit competitors from using synthetic data to develop competing products. Nowadays, there are news reports about unauthorized use behaviors that violate such usage terms. There is an emergent need for an auditing tool that assists them in collecting evidence of these unauthorized uses.
Novel Concept: We introduce the concept of synthetic artifact auditing. Given an artifact, it determines whether it is trained on or derived from LLM-generated synthetic data.
Novel Techniques: We propose an auditing framework with three methods that require no disclosure of proprietary training specifics: metric-based auditing, tuning-based auditing, and classification-based auditing. This framework is extendable, currently supporting auditing for classifiers, generators, and statistical plots.
Extensive Evaluation: We evaluate our auditing framework on seven downstream tasks across three training scenarios. The evaluation demonstrates the effectiveness of all proposed auditing methods across all these tasks.


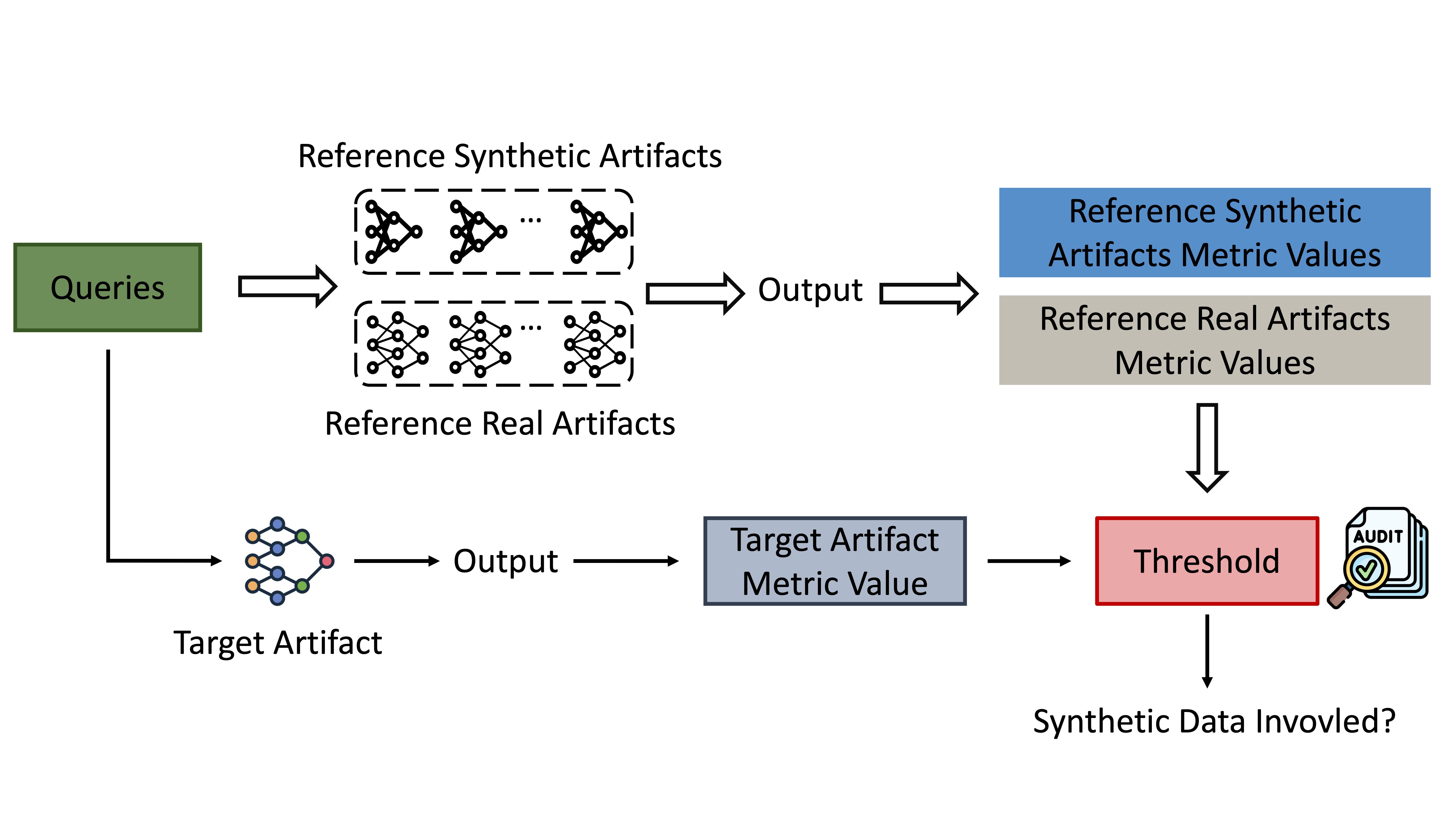
In general, our auditing framework follows a procedure:
Queries:
This paper evaluates the auditing framework on three text classification tasks, two text summarization tasks, and two data visualization tasks with four LLMs across three scenarios.
Our work has a real-world impact in promoting the responsible use of synthetic data and aligning with corresponding regulations and laws. Regulatory and governmental bodies are increasingly prioritizing data governance and transparency in the development of AI systems. For instance, the UK’s ICO requires documentation of synthetic data creation and its properties. Similarly, California recently passed Law AB 2013, mandating the disclosure of training datasets, including the use of synthetic data. Our framework provides a practical means for third parties to audit artifacts without requiring the disclosure of proprietary training details by artifact owners. This supports compliance with data governance and transparency requirements, enhances alignment with regulatory and legal standards (e.g., EU AI Act), and facilitates responsible and accountable AI practices.
@inproceedings{WYSBZ25,
title={Synthetic Artifact Auditing: Tracing LLM-Generated Synthetic Data Usage in Downstream Applications},
author={Wu, Yixin and Yang, Ziqing and Shen, Yun and Backes, Michael and Zhang, Yang},
booktitle={USENIX Security Symposium},
year={2025}
}