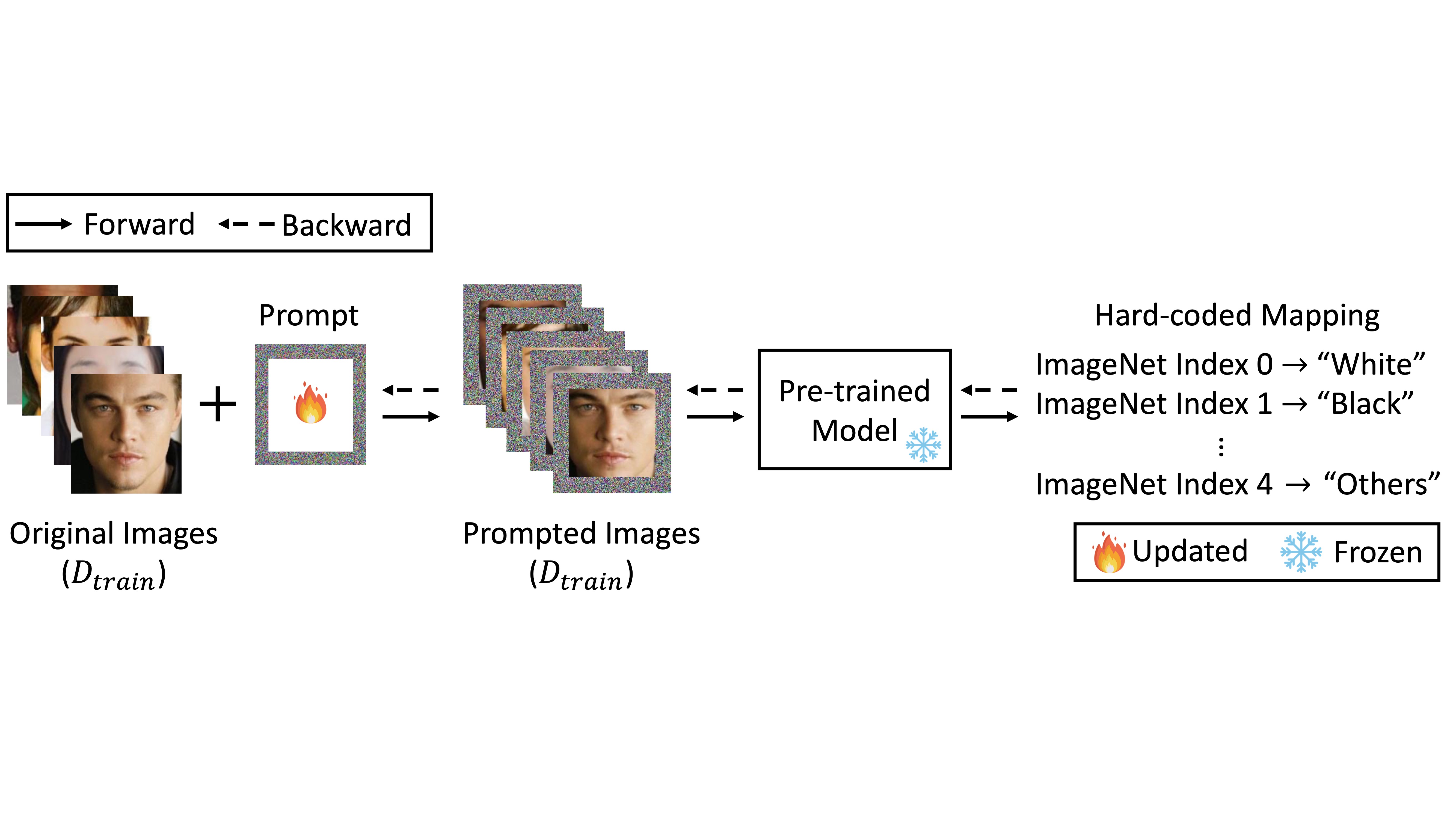
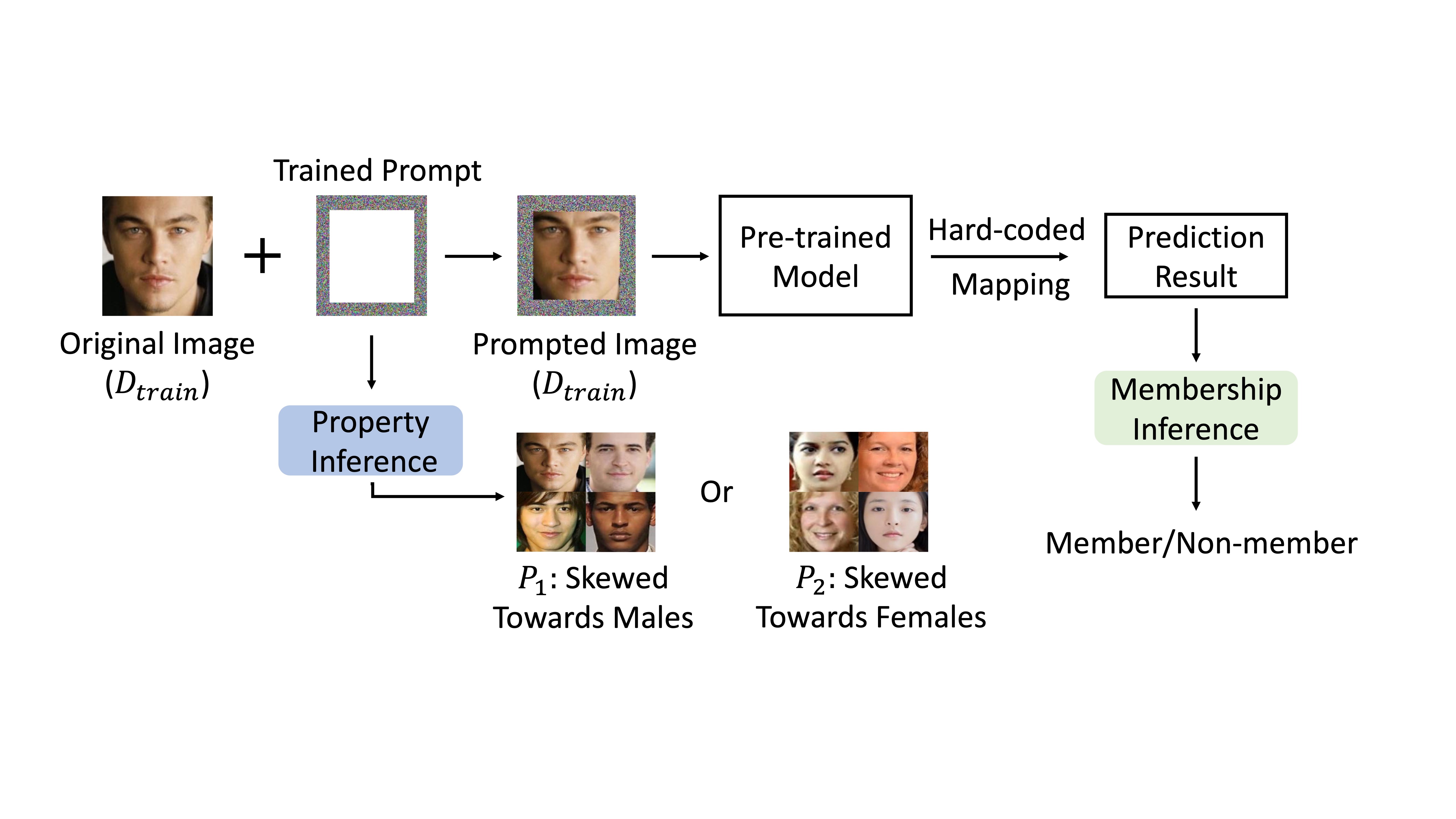
This work differs significantly from previous research on privacy risks. While prior studies primarily investigate the privacy risks of machine learning (ML) models, we focus on the privacy risks of prompts at the input level. Both ML models and prompts are essentially sets of parameters; however, prompts contain far fewer parameters than typical models (e.g., < 0.1%). In this manner, the information in the training dataset is heavily compressed during prompt learning.
This work presents an interesting conclusion: even though prompt learning heavily compresses training dataset information, it remains vulnerable to privacy attacks, leading to the leakage of privacy-sensitive information. Based on this conclusion, there are many potential directions for follow-up work. For example, investigating the privacy leakage of various adaptation paradigms. Given the large scale of modern pre-trained models, we often do not fine-tune the entire model. Instead, we freeze certain layers and optimize only a few. Considering our findings, we hypothesize that even when fine-tuning only a small number of parameters, models may still be vulnerable to privacy attacks. Moreover, we could explore other ML techniques related to compressed training information, such as model distillation, which might also lead to privacy leakage.
This work also has a real-world impact, particularly in light of existing and emerging privacy regulations such as the GDPR and the EU AI Act. Our findings suggest that tunable prompts could pose unforeseen privacy risks that may need to be addressed under these regulations. As AI legislation continues to evolve, it becomes increasingly important to develop privacy-preserving techniques tailored to prompt learning and other efficient adaptation paradigms.